Data Lake Intelligence with AtScale
In my recent Data Lake 2.0 article I described how the worlds of big data and cloud are coming together to reshape the concept of the data lake. The data lake is an important element of any modern data architecture, and the data lake footprint will continue to expand. However, the data lake investment is only one part of delivering a modern data architecture. At Yahoo!, in addition to building a Hadoop-based data lake, we also needed to solve the problem of connecting traditional business intelligence workloads to this Hadoop data. Although the term “Data Lake” didn’t exist back then, we were solving the problem of: “How can you deliver an interactive BI experience on top of a scale-out Data Lake” - it turns out we were pioneers in delivering Data Lake Intelligence.
Our experiences and learnings from those initial efforts led to the architecture that sits at the core of the AtScale Intelligence Platform. Because AtScale has been built from the ground up to deliver business-friendly insights from the vast amounts of information in data lakes, AtScale has experienced tremendous success and adoption in enterprises ranging from financial services, to retail to digital media. With the release of AtScale 6.5, we’ve continued to build on and expand AtScale’s ability to uniquely deliver on the promise of Data Lake Intelligence. If this sounds like something you might be interested in knowing more about… keep reading!
Read More
Topics:
Business Intelligence,
bi-on-hadoop,
Big Data,
Cloud,
BI,
Analytics,
BI on Big Data,
Data Strategy,
data driven
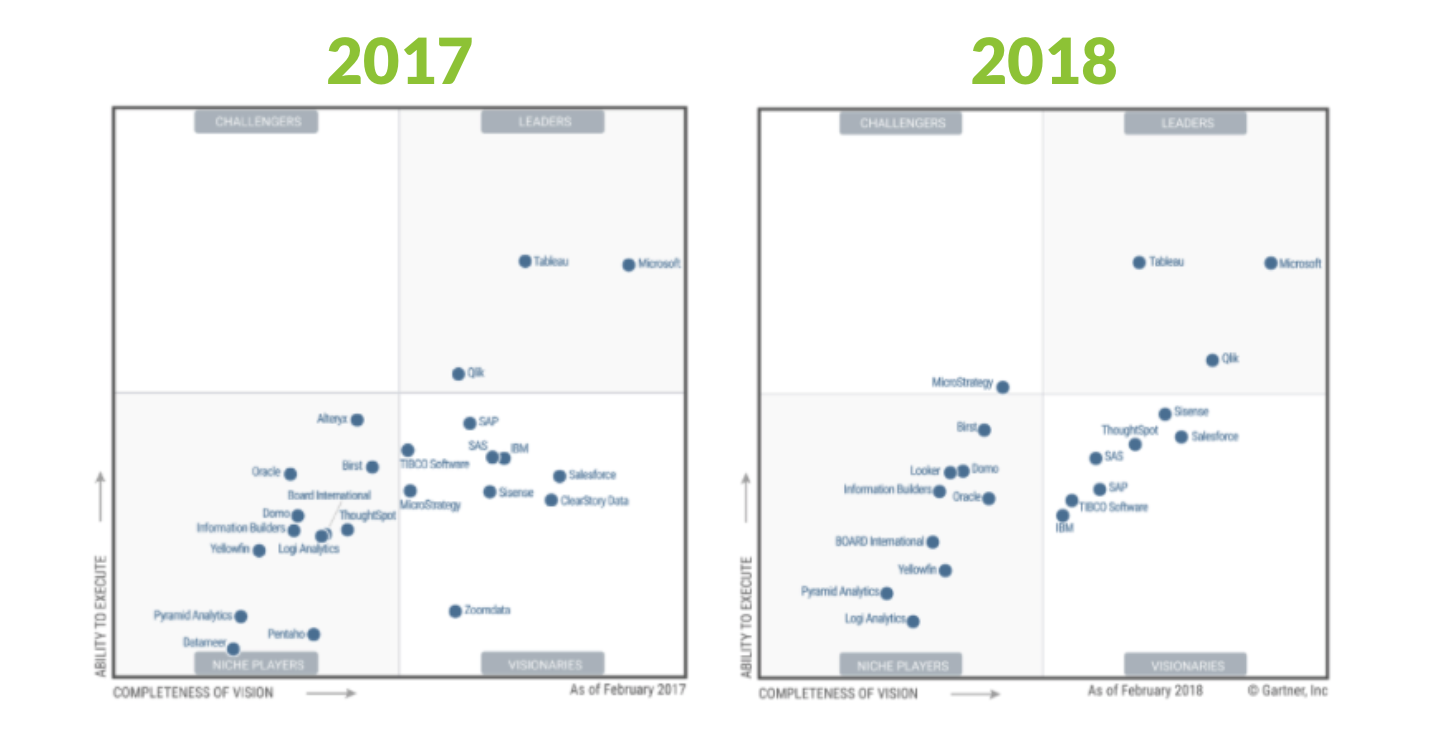
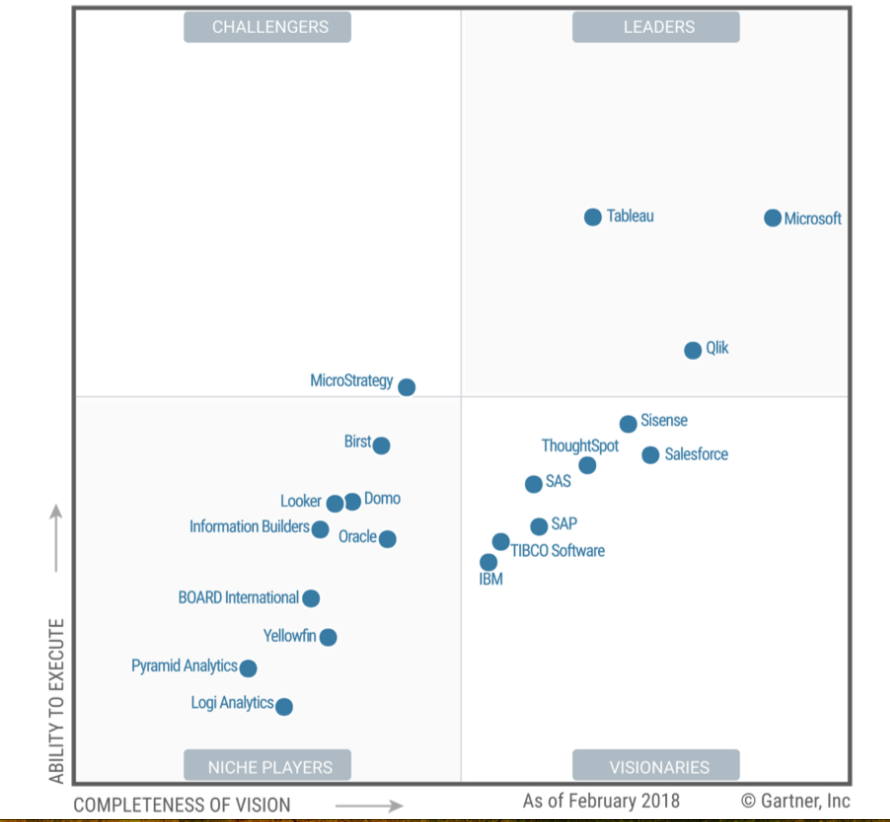
Yesterday, Gartner published the 2018 Magic Quadrant for Business Intelligence. The MQ research for BI has been in existence for close to a decade. It is THE document of reference for buyers of Business Intelligence technology.
At face value, not much seems to have changed...BUT, if you take a closer look, you'll notice that some of the biggest changes in the history of the Magic Quadrant just occurred....
Read More
Topics:
Tableau,
Gartner,
Business Intelligence,
GartnerBI,
BI on Big Data,
Microsoft,
Amazon,
microstrategy,
google
Additional contribution by: Santanu Chatterjee, Trystan Leftwich, Bryan Naden.
In the previous post we demonstrated how to model percentile estimates and use them in Tableau without moving large amounts of data. You may ask, "how accurate are the results and how much load is placed on the cluster?". In this post we discuss the accuracy and scaling properties of the AtScale percentile estimation algorithm.
To learn how to be a data driven orgazation, watch this webinar now!
Read More
Topics:
Hadoop,
bi-on-hadoop,
Analytics,
BI on Big Data,
percentiles
Additional contribution by: Santanu Chatterjee, Trystan Leftwich, Bryan Naden.
In the previous post, we discussed typical use cases for percentiles and the advantages of percentile estimates. In this post, we illustrate how to model percentile estimates with AtScale and use them from Tableau.
To learn how to be a data driven orgazation, check out this webinar!
Read More
Topics:
Hadoop,
bi-on-hadoop,
Analytics,
BI on Big Data,
percentiles
Every year, many of you reach out to thank us for our analysis of Gartner's famous Magic Quadrant for Business Intelligence. Thank you all for your feedback!
This year, we've decided to go one step further: in addition to our written analysis, we will be sharing our perspective as part of our upcoming "BI on The Data Lake Checklist" webinar.
Be sure to register here: the Gartner Magic Quadrant for Business Intelligence (BI) 2018 is bound to surprise you and our analysis will help you navigate its subtleties...
Read More
Topics:
Gartner
Additional contribution by: Santanu Chatterjee, Trystan Leftwich, Bryan Naden.
A new and powerful method of computing percentile estimates on Big Data is now available to you! By combining the well known t-Digest algorithm with AtScale’s semantic layer and smart aggregation features AtScale addresses gaps in both the Business Intelligence and Big Data landscapes. Most BI tools have features to compute and display various percentiles (i.e. medians, interquartile ranges, etc), but they move data for processing which dramatically limits the size of the analysis. The Hadoop-based SQL engines (Hive, Impala, Spark) can compute approximate percentiles on large datasets, however these expensive calculations are not aggregated and reused to answer similar queries. AtScale offers robust percentile estimates that work with AtScale’s semantic layer and aggregate tables to provide fast, accurate, and reusable percentile estimates.
In this three-part blog series we discuss the benefits of percentile estimates and how to compute them in a Big Data environment. Subscribe today to learn the best practices of percentile estimation on Big Data and more. Let's dive right in!
To learn how to be a data driven orgazation, check out this webinar!
Read More
Topics:
Hadoop,
bi-on-hadoop,
Analytics,
BI on Big Data,
percentiles
Does your decision-making process need an overhaul? In 2015, over 60% of the decisions made by companies were still based on ‘intuition’ or ‘experience’ of their executive team. With the rise of big data, it is imperative that we make use of such a valuable asset to make fact-based decisions and not just provide an opinion. This means that we need to become data-driven, of course this is easier said than done. It requires more than investing on the latest data and analytics software; it also requires cultural and organizational change.
Learn how industry leaders do it, register for our Best Practices Webinar!
Read More
Topics:
bi-on-hadoop,
culture,
Analytics,
BI on Big Data,
data driven
While it may be tempting to focus our efforts only on self-service BI in terms of security and access control mechanisms, it is important to also place emphasis on economies to achieve success. When an enterprise develops a self-service BI environment, it undoubtedly means that their IT team adopts the role of a service provider. Data and services become available to internal business users for a price. What are these hidden costs?
Read More
Topics:
Business Intelligence,
Big Data,
BI,
Data,
BI on Big Data
A version of this article originally appeared on the Cloudera VISION blog.
One of my favorite parts of my role is that I get to spend time with customers and prospects, learning what’s important to them as they move to a modern data architecture. Lately, a consistent set of six themes has emerged during these discussions. The themes span industries, use cases and geographies, and I’ve come to think of them as the key principles underlying an enterprise data architecture.
Whether you’re responsible for data, systems, analysis, strategy or results, you can use these principles to help you navigate the fast-paced modern world of data and decisions. Think of them as the foundation for data architecture that will allow your business to run at an optimized level today, and into the future.
Read More
Topics:
Hadoop,
Business Intelligence,
Big Data,
Hadoop Summit,
Chief Data Officer
I am a software engineer and I like abstractions. I like abstractions because done correctly an abstraction will factor complexity down to a level where I don’t have to spend any brain cycles thinking about it. Abstraction lets me work with a well thought out interface designed to let me accomplish more without having to always consider the system at a molecular level.
It turns out business people also like abstraction. This shouldn’t be surprising as businesses model complex real world concepts where the details matter. From calculation to contextual meaning, abstraction helps with correctness and understanding.
Read More
Topics:
Semantic Layer